Datalake, Datawarehouse and Datamart
These are what we build on Big Data Platforms.
DATA ENGINEERING
9/8/20243 min read
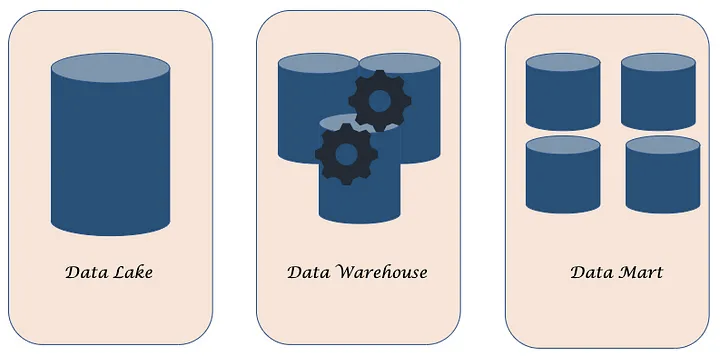
In this article we discuss about the things we generally build on Big-Data platforms to store, process and analyse the data. They are Datalake, Datawarehouse and Datamarts. Though they appear to be similar and often interchangeably used, they are built for different purposes and have lot of differences between them. Let’s start with what these are individually:
Datalake:
A data lake is a centralised repository that allows you to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data, and run different types of analytics — from dashboards and visualisations to big data processing, real-time analytics, and machine learning to guide better decisions.
Why do we need a data lake?
Organisations need need a cheap way to store different types of data in large quantities.
If there is no plan for what to do with the data, but you have a strong intent to use it at some point.
Examples:
Manufacturing:Companies can use data lakes to implement predictive maintenance and improve operating efficiency.
Marketing:Marketers gather information about customers from many sources, including display advertising, email campaigns, social media platforms and third-party providers of demographic and market information.
Supply chain:A data lake can collect information from internal ordering and warehouse management systems, suppliers and shippers, as well as external sources such as weather forecasts.
Datawarehouse:
A data warehouse is an aggregation of data from many sources to a single, centralised repository that unifies the data qualities and format, that support analytical reporting, structured and/or ad hoc queries, and decision making. The goal of a data warehouse is to create a trove of historical data that can be retrieved and analysed to provide useful insight into the organisation’s operations.
These systems must be scalable, reliable, and secure enough for regulated industries, as well as flexible enough to support a wide variety of data types and use cases. The requirements go way beyond the capabilities of any traditional database. That’s where the data warehouse comes in.
Examples:
Investment and Insurance companies use data warehouses to primarily analyse customer and market trends and allied data patterns.
Retail chains use data warehouses for marketing and distribution, so they can track items, examine pricing policies and analyse buying trends of customers.
Healthcare companies, on the other hand, use data warehouse concepts to generate treatment reports, share data with insurance companies and in research and medical units.
Datamart:
A data mart is essentially a set of dashboards that analyse data from a subset of a data warehouse or lake for a particular business function. That is, a data mart combines a part of a data warehouse or lake, curated for a team or an analytical domain, with the dashboards and visualisations that analyse that data.
There are three types of data marts:
A dependent data mart, which consists of enterprise data warehouse partitions. It is a subset of primary data in a warehouse.
An independent data mart, which is a standalone system, siloed to a specific part of the business.
A hybrid data mart, which consists of data from a warehouse and independent sources. This type typically provides faster data access and a user-friendly interface.
Examples:
Datamart created for a specific department in an organisation such as Marketing, Sales, HR or Finance.
Differences between Datalake, Datawarehouse and Datamart:
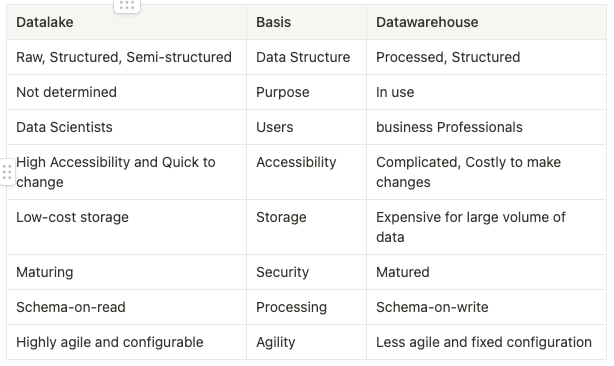
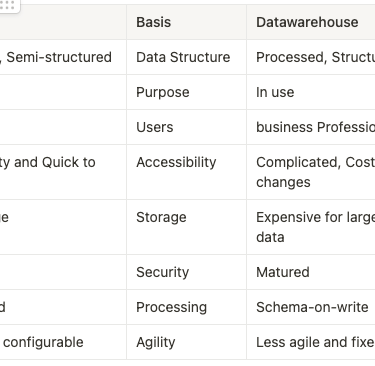
Hope this gives a good start to building data solutions on big-data platforms. Next, we will list down the guidelines and principles around building these solutions, the challenges faced etc in the subsequent articles.